I’ve been to a couple of conferences already this year, including Lambda Days 2019, where I saw a whole bunch of good talks. Two talks in particular stick out in my mind: Diving into Merkle Trees, by Pedro Tavares, and Bridging the Divide: A Philosophy of Library Design, by Brooklyn Zelenka.
The first talk was about Merkle Trees, we’ll get into what they are and how we use them in Horde shortly. The second talk was about library design, and got me thinking about composability. Both factored heavily into recent performance increases in Horde. Horde v0.5.0 was released just a short while ago, and in What’s new in Horde 0.5.0 I wrote:
Horde should be able to handle tens of thousands of processes without breaking a sweat
This blog post is about the developments that led to these improvements.
(If you don’t know what Horde is, read the introductory blog post.)
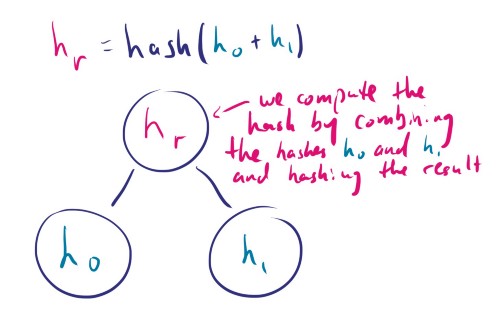
So, what is a Merkle Tree, otherwise known as a Hash Tree? It is a binary tree, where the leaves are representing some data, maybe a file, or in our case, a map. The nodes of the tree also have hashes, which we calculate by combining the hashes of the child nodes, and hashing that. This continues up the tree until the root node only has one hash, representing the entire tree.
Merkle Trees have some very interesting properties, as it turns out. For example, if we compare 2 merkle trees, we can tell whether the two trees are identical just by comparing the top nodes. This works because the root node hash is essentially a hash of the entire data structure. (This is not actually all that revolutionary though, since we can also just take the complete hash of the entire data structure, and compare that, and we would get the same result.)
Much more interesting: we can tell, by starting at the top and working our way down, where the differences are in two trees by comparing the hashes. In fact, we can find a single difference in constant time! Now we’re talking!
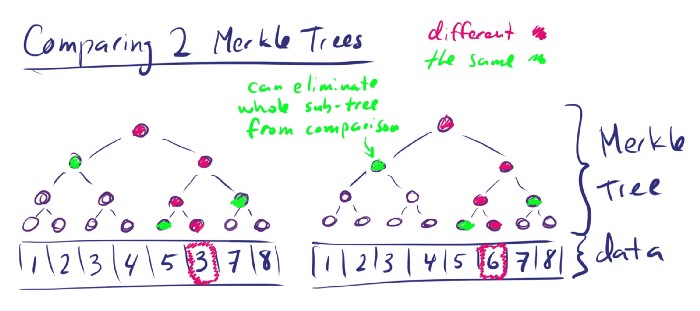
This is just a toy example, but it should illustrate the comparisons we have to make to isolate 1 difference between two sets of data. This has applications in peer to peer file sharing, for example. By comparing the merkle tree representation of the file you have on disk with the merkle tree representation of the canonical file, you can tell very quickly which blocks either still need to be downloaded or are corrupt.
So this is great, we can compare files of similar length, and do it quickly. But what if we want to compare two maps? We need a way to encode a map into a merkle tree.
After puzzling over this for a while and reading some more papers, I came to a solution: hash the key, and use that hash to determine the “bucket” the key/value pair will reside in.
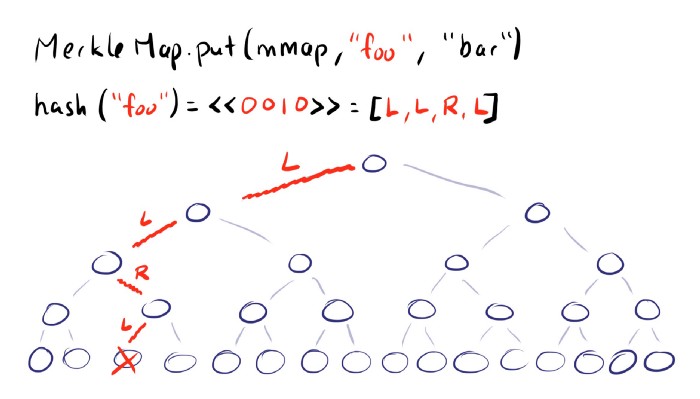
If you use a 32-bit hash, you can have a tree with 32 layers. If you use a 64-bit hash, you can have a tree with 64 layers. This is probably overkill, however, as a 32-layer tree has more than 4 billion “buckets”. To deal with possible hash collisions, we store the keys / values in a sorted list at the leaves of the tree. This enables us to generate consistent hashes, which means we won’t get any false-negatives (map that are identical but don’t end up with the same hash at the root node).
This brings us to the second topic of this blog post: composability. At the time I was working on implementing merkle trees in Horde, I happened to attend Brooklyn Zelenka’s keynote for the second time (link at the top). Her talk was about library design. I was working on a library. She tried to drive home the idea that the best designs were composable, and finally I got it:
Instead of building Merkle Trees into Horde, I should see if I can build a general-purpose library that gives me the same advantage.
Enter MerkleMap.
MerkleMap is exactly what it sounds like: it’s a map, augmented with a Merkle Tree. With MerkleMap you can compare large maps blazingly fast. MerkleMap does for Map what MapSet does for Set (or at least, in my hubristic brain).
MerkleMap implements all of Map’s functions, and adds one of its own: MerkleMap.diff_keys/2. With diff_keys, you can compute the keys that differ between two maps. This basic function is powering all of the speed increases in the rest of the functions.
Let’s just cut to the chase: how fast is it? As my artificial and incomplete benchmarks show: very fast indeed (DISCLAIMER: your mileage may vary significantly depending on your exact workload).
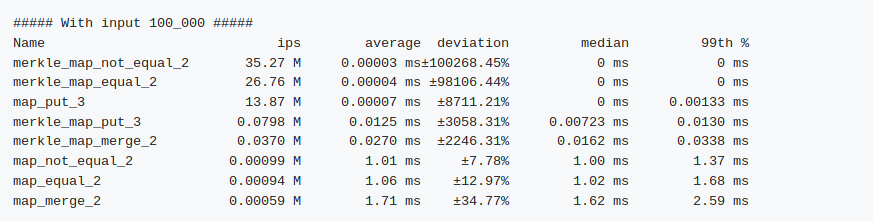
For a map with 100_000 key/value pairs, with one key having a different value (I said this benchmark was artificial! ), MerkleMap outperforms Map for Map.equal/2, taking on average 0.00004ms to complete vs 1.06ms. This should not surprise anyone, however, because MerkleMap does it in O(1), and Map is constrained to checking every single key / value pair, for O(n).
Perhaps more surprising is the advantage shown by MerkleMap.merge/2. But again, here we can do some fun tricks to complete our merge in 0.027ms instead of Map’s 1.71ms. (in other words, in just 1.5% of the time).
If you are doing many more comparisons than mutations, MerkleMap might be faster for you.
I should not forget to mention that Map.put/3 remains much faster than MerkleMap.put/3. This illustrates one of the trade-offs that MerkleMap makes (the other one being memory usage). You pay a little more up-front for potentially huge savings later on. If you are doing many more comparisons than mutations, MerkleMap might be faster for you. If you’re not, however, you’ll only be slowing down your program by using MerkleMap. Your mileage may vary!
Most importantly, MerkleMap is a drop-in replacement for Map. So you could conceivably run :%s/Map/MerkleMap/g on your entire file tree, and things would keep working (if you don’t use any map literals anywhere, that is). Your application probably won’t get faster this way though, I have had the best success using MerkleMap sparingly, since actually quite a few maps don’t undergo enough comparison operations to justify the tradeoffs presented by MerkleMap.
Horde’s main background activity is continuously syncing a map between the nodes in your cluster. Correspondingly, Horde typically does many many times more comparisons than updates. MerkleMap allows us to reduce the computational complexity of doing a single update to constant time, which is a huge win.
I hope that by providing MerkleMap as an independent library, that others can benefit from it. I’m really excited to see how the community will put this library to use in other projects. If you do end up using it, or have any questions, feel free to ping me on Slack or Twitter.
[2] Bridging the Divide: A Philosophy of Library Design
[4] Horde
[5] MerkleMap
Get the ball rolling on your new project, fill out the form below and we'll be in touch quickly.
By: Derek Kraan / 2023-05-24

By: Derek Kraan / 2020-12-03

By: Derek Kraan / 2020-09-03

By: Derek Kraan / 2020-04-23

By: Derek Kraan / 2019-12-06

By: Derek Kraan / 2019-07-22