
It’s not every day that you get to contribute a PR to a well-used library that improves its performance under common circumstances by 100% to 300+%. This week it was my turn! This blog post will cover these recent improvements.
Last week I got called in to debug some performance issues for one of our clients. We looked under every rock for an answer, and after a week of debugging, and fixing multiple tangentially related issues, we realized that there was likely something funny going on in EventStore. For reasons unclear to us, it looked like there was sometimes a lot of waiting happening while inserting new events into the database. Our analysis identified the UPDATE lock on the $all stream as the likely suspect, but investigation again hit a dead end when we asked the author of the library how many events per second the event store should be able to handle. Basically, his answer was: orders of magnitude more than what we were doing even during peak times.
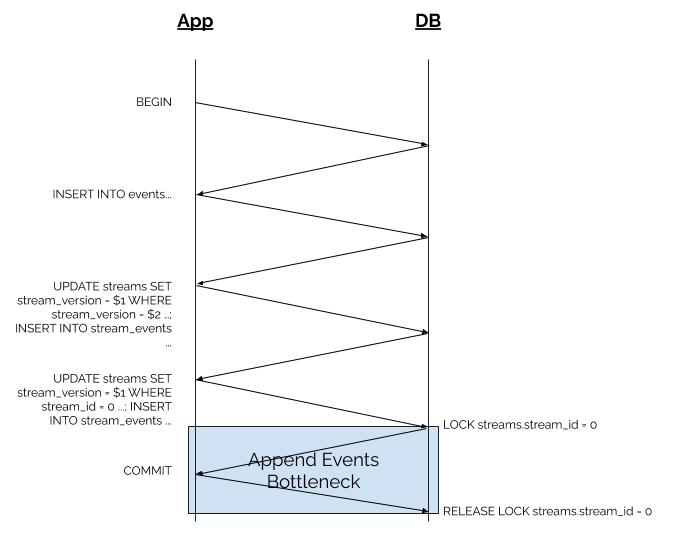
Something still seemed fishy though, so I dove further into the EventStore code to figure out exactly what was happening when an event gets added to the event store. The basic sequence looks like this:
BEGIN
INSERT INTO events ...
UPDATE streams SET stream_version = $1 WHERE stream_id = $2 ...; INSERT INTO stream_events ...
UPDATE streams SET stream_version = $1 WHERE stream_id = 0 ...; INSERT INTO stream_events ...
COMMIT
This doesn’t look super suspicous at first glance, but look carefully at #4. The UPDATE query on streams where stream_id = 0 is acquiring an exclusive update row lock on this particular row.
Backing up a step, EventStore works with the concept of “streams”. Roughly speaking, each “entity” in your system will have one “stream”, but there is also the $all stream, with stream_id = 0, that every event gets linked in to, sequentially. Linking the events into the $all stream is what is happening at step 4, and it is this operation that is a potential choke-point for the system.
So back to the row lock, it is only released once the transaction has been committed, and the structure of this sequence means that there is a single network round trip from the DB to the application server and back before COMMIT happens. This imposes a theoretical global limit on the throughput of appending events to the event store, related to the network latency between the application and DB server. If latency is only 5ms, we are limited to 200 batches per second. If network performance is degraded to the point that latency goes up to 100ms, then you can only get 10 batches of events appended to the DB per second. This has the potential to render a service completely unusable.
The first fallacy of distributed computing is the network is reliable, and the second one is latency is zero, but when we run benchmarks, we typically do this on a single machine (our development machine), where latency is for all intents and purposes 0. The earlier benchmarks were lying to us.
Once you have identified the problem, the fix is conceptually simple: bundle the queries into one big one and send it to Postgres all at once. This avoids the network round trip between locking the $all stream, and releasing the lock, breaking the relationship between DB latency and DB throughput.
It’s always good to benchmark our changes, especially when we are specifically looking to improve performance. In order to benchmark this, however, I needed to be able to control the latency between the application (in this case the script running my benchmarks) and the database server. Running the benchmarks on real hardware is one option, but it’s hard to actually control the latency in such a case. I googled around a bit and found this blog post which does a pretty good job of describing how to do this with docker. I’m going to distill the important bits and present them here.
The basic idea is to install a package, iproute2, in the docker container of our database, and then use the included tc utility to add however much latency we want.
I started with a super simple Dockerfile:
FROM postgres:12
RUN apt-get update
RUN apt-get install iproute2 --yesWhen the container is running, run the following command to add latency (in my case I’m using docker-compose): docker-compose exec [container_name] tc qdisc add dev eth0 root netem delay 5ms
Confirm that latency is what you expect it to be using ping. You can get the ip address of a docker container as follows: docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' [container_name]
Note: you must restart the container if you wish to set a different latency.
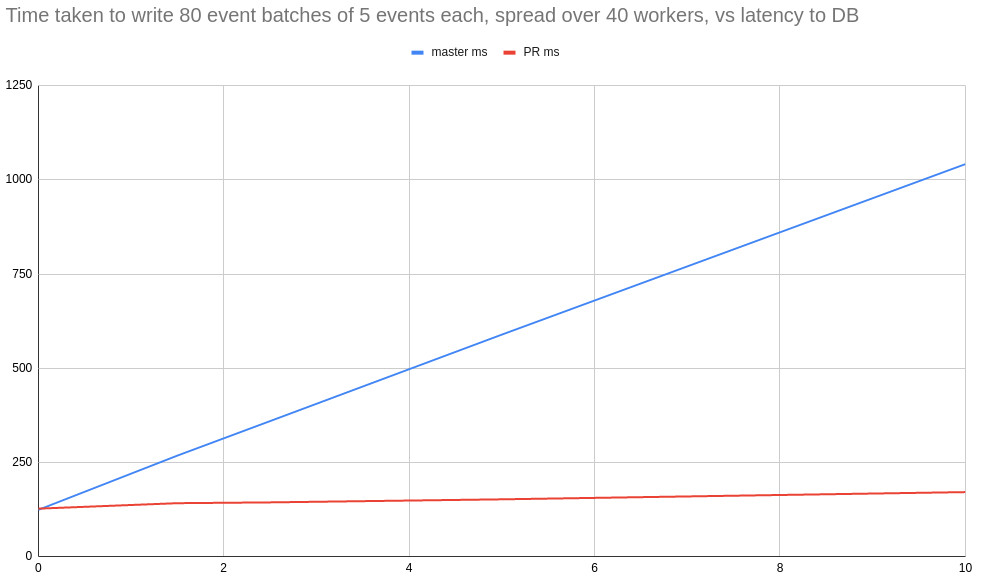
I ran a large number of benchmarks, each inserting a single batch of events into 80 streams. These 80 streams were divided among a number of processes simultaneously inserting events, but the unit workload (# of event batches inserted per test run) remained the same. The following parameters were varied:
Looking at 40 simultaneous workers, because that is the case that most closely resembles production loads, the overall results showed that for inserting events in batches of 100, at network latency >=5ms, the PR changes were faster, increasing to 5.3X faster at 50ms latency.
Inserting events in batches of 5, the results were even more dramatic, with the PR changes being 1.9X faster at 1.5ms latency (which is a common, everyday DB latency), up to 6.1X faster at 10ms of latency to the DB. I would expect this trend to continue as DB latency increased, owing to the theoretical limit identified above.
You can expect these changes to make their way into EventStore 1.2.1 shortly. These changes mean a large improvement to performance under normal conditions, and a vast improvement under degraded network conditions.
I also have to thank Ben Smith, the author of Commanded and EventStore. He has been super helpful answering all kinds of questions, humouring me while I went down at least 3 or 4 rabbit holes that ended up in dead ends, eventually helping me pinpoint these performance issues and taking the first stab at a potential solution, and proofreading this blog post.
Get the ball rolling on your new project, fill out the form below and we'll be in touch quickly.
By: Derek Kraan / 2023-05-24
By: Derek Kraan / 2020-12-03

By: Derek Kraan / 2020-09-03

By: Derek Kraan / 2020-04-23

By: Derek Kraan / 2019-12-06

By: Derek Kraan / 2019-07-22