
Note: This guide has fallen out of date. There is an up to date version in the official documentation: https://hexdocs.pm/horde/getting_started.html
If you’re new to Horde, you might want to start by reading Introducing Horde — a distributed Supervisor in Elixir. This tutorial shows the steps needed to build a distributed system using Horde. I’ll start with a quick introduction to Erlang clustering and move on to Horde.Supervisor and Horde.Registry.
I have also turned this guide into an example app that you can use as another point of reference. The README includes steps for how you can run it.
To connect different instances of the BEAM together, we will use Erlang clustering. There are two basic requirements: a node must have a unique name in the cluster, and a node must share the same cookie as the other node. We can set the name and the cookie using ERL_AFLAGS.
This can be illustrated by running two instances of iex and connecting them to each other:
ERL_AFLAGS="-name node_1@127.0.0.1 -setcookie cookiexyz" iex -S mix
ERL_AFLAGS="-name node_2@127.0.0.1 -setcookie cookiexyz" iex -S mix
Then in the first console, run Node.connect(:"node_2@127.0.0.1"). If it returned true then the connection was established. Run Node.list() in both consoles to confirm that the nodes are connected.
Horde assumes that you will manage Erlang clustering yourself. There are also libraries that might make this easier for you. You can start with a simple solution (see the example app for an idea) and move on to something more complex as your needs change.
You can start Horde.Supervisor as you would a regular Supervisor. Horde.Supervisor is API-compatible with Supervisor. Let’s take a look at how that might look in the application.ex file in your project:
defmodule HelloWorld.Application do
use Application
def start(_type, _args) do
children = [
{
Horde.Supervisor, name: HelloWorld.HelloSupervisor,
strategy: :one_for_one, children: []
}
]
opts = [strategy: :one_for_one, name: HelloWorld.Supervisor]
Supervisor.start_link(children, opts)
end
end
Starting a child can be done by running Horde.Supervisor.start_child(HelloWorld.HelloSupervisor, SayHello).
All functions that Supervisor exposes are also mirrored in Horde.Supervisor, so stop_child, terminate_child, etc, all work the way you’re used to.
At this point you’ve got a single instance of Horde.Supervisor running on a node, or maybe you’ve started a second node and also have an instance of Horde.Supervisor running there. The whole idea of course is to link them together so that you have a distributed supervisor! This is where Horde.Cluster comes in. Let’s say you started Horde.Supervisor on two nodes, registered under the name HelloWorld.HelloSupervisor, as in the example above. Then you can link them together with the following code: Horde.Cluster.join_hordes(HelloWorld.HelloSupervisor, {HelloWorld.HelloSupervisor, other_node}), where other_node is a member of Node.list().
Now you have linked together the supervisors and have a distributed supervisor. Horde will merge both supervisors’ states and ensure that there is only one process running per id. Similarly, when a node is removed from the cluster or dies, Horde will ensure that any processes that were running on it are restarted on other nodes.
For a basic example of how you can glue together multiple instances of Horde.Supervisor into a single distributed supervisor, refer to the example app.
At this point you should play around with your nodes to get a feel for Horde’s behaviour when you start a child, kill a node, add a new node, etc. You can play with and extend the example app. For example, try adding a third or fourth node to the cluster, and then try starting some child processes. Take note of where they get started, and what happens when you then stop one of the nodes.
At some point you’re going to start multiple processes under a distributed supervisor, and you’ll want to communicate with them. The question is: how? With a normal application, you would name your processes (which is called “registering” them), and then refer to them by that name (eg: GenServer.call(SayHello, :how_many)) but this mechanism is scoped to a single node. If you know where a process is running, you can still address it with GenServer.call({SayHello, node}, :how_many) but Horde.Supervisor starts new processes on a random node, so how can you know which node your process is running on to address it with {name, node}? The answer is: we need to use Horde.Registry.
Horde.Registry is a distributed process registry. That means that you can register a process with it, and then access that process from any location in your cluster.
There are a couple of ways you can do this. For example, you can call Horde.Registry.register(registry, :foo) from within a process (eg, the init/1 callback of a GenServer) to register it. The pid of this process can then be found by calling Horde.Registry.lookup(registry, :foo) from any node in the cluster. This will work, but there is a nicer approach.
Another method is by using a “via tuple”. Via tuples are a mechanism in GenServer that tells a GenServer how it can retrieve the location of a process by using a registry. The format of a via tuple is as follows: {:via, Horde.Registry, {HelloWorld.HelloRegistry, name}}. In other words, if you call GenServer.call({:via, Horde.Registry, {HelloWorld.HelloRegistry, :foo}}, :action) then GenServer will call Horde.Registry.send({HelloWorld.HelloRegistry, :foo}, :action). (GenServer will actually not send :action, but a GenServer-specific message, but we can safely ignore that detail).
This might not actually seem all that helpful at first glance. Why would you want to write out that long {:via, _, _} tuple every time you want to address a process? Well it turns out that we can also use a via tuple to register a process with a registry automatically. So GenServer will call Horde.Registry.register_name/2 for you! Still not convinced? Try putting the details in a function (example: SayHello.via_tuple/1). In the example app, for example, you can communicate with the SayHello process by calling SayHello.how_many?, which calls GenServer.call(via_tuple(name), :how_many?). Via tuples can be a nice way to hide complexity. In the example app, you can safely communicate with SayHello processes without having to know that they reside on another node.
One of the best things about Horde is that its Supervisor and Registry both function as OTP building blocks in a way you’re familiar with. This means that common OTP patterns can be utilized with Horde to build distributed supervision trees of arbitrary complexity combined with distributed registries. I’ve included a supervision tree diagram here for illustration.
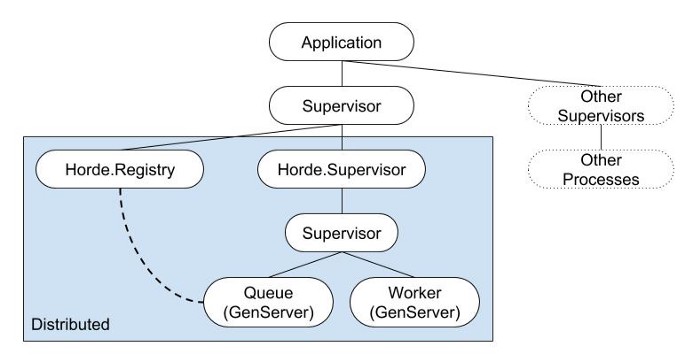
Horde.Supervisor and Horde.Registry are just two new tools in your OTP toolbox.
Horde is a work in progress. If you have any questions about this guide, please feel free to leave a comment below, then I can improve this guide. Pull requests (for code, but also for documentation improvements) are also very welcome!
Get the ball rolling on your new project, fill out the form below and we'll be in touch quickly.
By: Derek Kraan / 2023-05-24

By: Derek Kraan / 2020-12-03

By: Derek Kraan / 2020-09-03

By: Derek Kraan / 2020-04-23

By: Derek Kraan / 2019-12-06

By: Derek Kraan / 2019-07-22